
Artikeln är en del av ett kommersiellt samarbete mellan MongoDB och Datormagazin.
Med sin dokumentorienterade, JSON-likande lagring, höga flexibilitet och horisontella skalbarhet – tillsammans med unika indexerings- och sökmöjligheter – är MongoDB det givna valet för utvecklare som söker en NoSQL-databaslösning.
Vi har följt MongoDB under sin expansion på den nordiska marknaden, vilken fick lite av ett avstamp med eventet MongoDB .local Stockholm tidigare i år. Vi har även tittar närmare på företagets korta men lyckade resa, där vi gett en överblick över företagets tjänster och lösningar. Denna gång ska vi gå lite djupare in på några av de funktioner som gör MongoDB unika och som tar användandet långt längre än till att bara vara en dokumentorienterad datas.
Modern struktur
Databaser har funnit med oss nästan sedan datorerna gjorde sitt intåg på marknaden, och de första kommersiella lösningarna såg dagens ljus redan i slutet av 1970-talet tillsammans med då kända ABC 80. När vi pratar databaser anno 2024 tänker många troligen på Oracle, SQL eller världen största, fria, databas MySQL. Men trots att dessa funnits med länge och såklart utvecklats efter hand, kan det ibland upplevas som att de i första hand är anpassade och uppbyggda för den typ av data och infrastruktur som var vanligast för ett decennium sedan.

I takt med att internet och framför allt molnbaserade tjänster vuxit och i dag till stora delar dominerar de trafikvägar som vår data transporteras, lagras och bearbetas, så har även behovet på en nyare, mer flexibel, typ av databasstruktur vuxit fram. Detta är även lite av anledningen till att MongoDB grundades, och framför allt den primära anledningen till att MongoDB vuxit så snabbt och på mindre än tio år placeras som världens femte populäraste databas, men högst rankad NoSQL-databas, enligt DB-Engines.
Vad är det då som skiljer MongoDB:s dokumentorienterade struktur jämfört med de mer klassiska relationsdatabaserna?
En dokumentdatabas är en typ av NoSQL-databas som kan användas för att lagra och fråga data som JSON-liknande dokument. JSON, eller JavaScript Object Notation som är dess fullständiga namn, är ett öppet datautbytesformat som är både mänskligt och maskinläsbart.
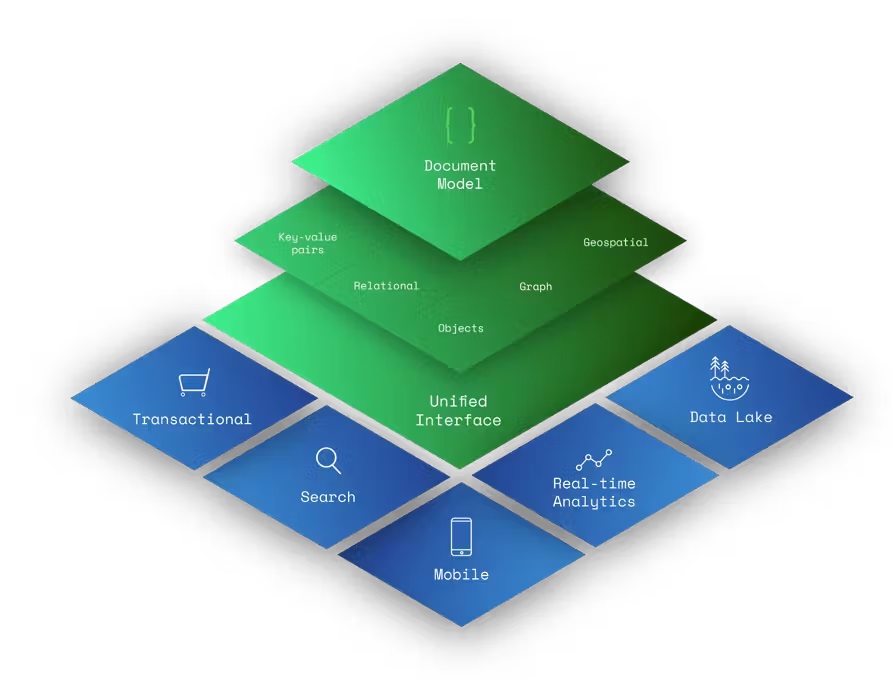
Dokument tillåter utvecklare att representera sina data som identiska objekt i både sin kod och databasen. Det krävs ingen data- eller typtransformation mellan lagring och användning av en datapunkt. Den flexibla, semistrukturerade och hierarkiska karaktären hos dokument och dokumentdatabaser gör att de kan utvecklas med applikationernas och utvecklarnas behov. Till detta möjliggör dokumentdatabaser flexibel indexering, kraftfulla ad hoc-frågor och analys över samlingar av dokument och även fysiska platser.
Alternativa användarexempel
Tack vare att JSON-dokument mappas mot objekt – en vanlig datatyp i de flesta programmeringsspråk – kan utvecklare som bygger applikationer skapa och uppdatera dokument direkt från koden på ett flexibelt sätt.
Detta innebär att de behöver lägga mindre tid på att skapa datamodeller i förväg, vilket gör applikationsutvecklingen snabbare och mer effektiv.
En dokumentorienterad databas låter dig även skapa flera dokument med olika fält inom samma samling. Denna praxis, kallad polymorfism, kan vara en klar fördel när du exempelvis lagrar ostrukturerade data som e-postmeddelanden eller inlägg på sociala medier. Vissa dokumentdatabaser erbjuder även schemavalidering, vilket gör det möjligt att införa vissa begränsningar för strukturen.
Till detta har dokumentdatabaser inbyggda distributionsmöjligheter vilket gör att vi kan skala dem horisontellt över flera servrar utan att prestandan påverkas negativt, vilket även kan ge en lägre TCO (total cost of ownership eller total ägandekostnad på svenska). Dessutom erbjuder dokumentdatabaser feltolerans och tillgänglighet genom inbyggd replikering.
Dokumentdatabaser kan användas i ett stort antal fall, men för att få en bättre förståelse över nyttan lyfter vi fram tre typer av användningsområden.
- Alla former av innehållshantering
En dokumentdatabas är ett utmärkt val för olika typer av innehållshanteringsapplikationer som bloggar och videoplattformar. Med en dokumentdatabas kan varje enhet som söks och spåras, lagras som ett enda dokument. Dokumentdatabasen blir på detta sätt ett mer intuitivt sätt för en utvecklare att uppdatera och arbeta med en applikation när kraven utvecklas. Om datamodellen behöver ändras behöver dessutom bara de berörda dokumenten uppdateras, vilket sparar tid och resurser. Till detta krävs ingen schemauppdatering, och inga driftstopp blir nödvändiga för att göra ändringar. - Kataloger
Dokumentdatabaser är effektiva för att lagra kataloginformation. Till exempel: I en e-handelsapplikation har olika produkter vanligtvis olika antal attribut. Att hantera tusentals attribut i relationsdatabaser är ineffektivt och läsprestanda påverkas negativt. Med hjälp av en dokumentdatabas kan varje produkts attribut beskrivas i ett enda dokument för enkel hantering och snabbare läshastighet. Att ändra attributen för en produkt påverkar dessutom inte andra, vilket underlättar arbetet. - Sensorhantering
Internet of things (IOT) har resulterat i att organisationer regelbundet samlar in data från smarta enheter som olika sensorer och mätare i varierande miljöer. Data från sensorerna kommer vanligtvis in som en kontinuerlig ström av variabla värden. På grund av latensproblem kan vissa dataobjekt vara ofullständiga, duplicerade eller saknade. Dessutom behöver stora volymer data samlas in innan den kan filtreras eller sammanfattas för analys.
Dokumentbaserad lagring är i detta fall mer praktisk, då sensordata snabbt kan lagras som den är, utan att den behöver rensas eller behandlas så att den överensstämmer med förutbestämda scheman. Det är dessutom möjligt att enkelt skala uppsättningen efter behov och även ta bort hela dokument när analysen är klar.
Artificiell intelligens och kapaciteten i Vector Search
MongoDB Atlas Vector Search släpptes som en allmänt tillgänglig version den fjärde december 2023, detta efter att tjänsten funnits som en publik förhandsversion under en period. Den efterlängtade funktionen öppnar för nya sökmöjligheter och ger utvecklare möjlighet att bygga intelligenta AI-drivna applikationer som drivs av semantisk sökning och generativ AI, över alla tänkbara datatyper, från olika databaser genom MongoDB Query API.
Det mest revolutionerande med MongoDB Atlas Vector Search är att tjänsten löser utmaningen att tillhandahålla relevanta resultat även vid de tillfällen som användare inte vet vad de letar efter, och den integrerar med maskininlärningsmodeller för att hitta resultat som liknar och sträcker sig över nästan alla typer av data.
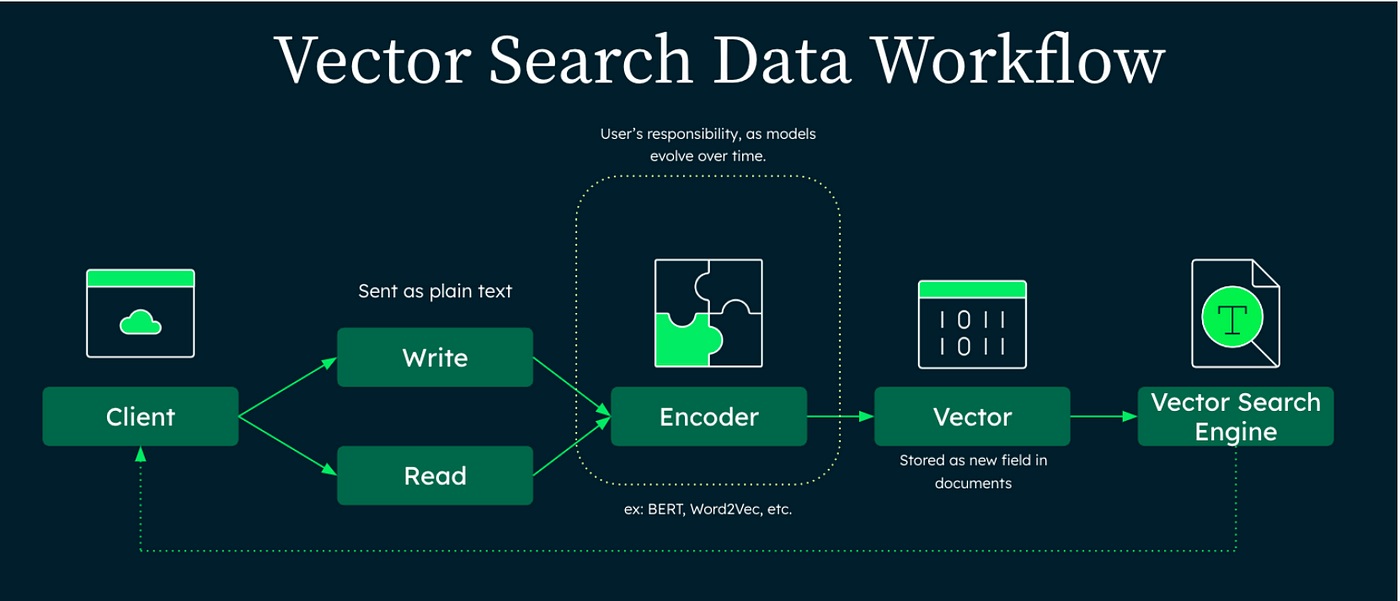
För att enkelt förstå syftet med MongoDB Atlas Vector Search kan du föreställa dig att du söker efter något, men inte riktigt vet allt som behövs för att kunna genomföra sökningen. Det kan till exempel handla om att du kommer ihåg några scener i en film och ungefär hur gammal den är, men inte minns vilka som spelar i den eller vad den heter. Eller tänk dig att du använder en LLM-motor (ett Python-bibliotek) som bara har data som sträcker sig till 2020, men du behöver data från senare år. I dessa och likande fall kan MongoDB Atlas Vector Search vara precis det du söker.
Att tjänsten är efterlängtad märks inte minst på att MongoDB Atlas Vector Search, redan inom en femmånaders period från det att tjänsten presenterats som en offentlig förhandsvisning, har fått det högsta så kallade developer net promoter score (NPS) som går att erhålla. Tjänsten är även den näst mest använda vektor-databasen enligt Retool’s State of AI report.
I grunden finns två primära användarfall där MongoDB Atlas Vector Search används för att bygga nästa generations smarta appar:
- Semantisk sökning
Söka och hitta relevanta resultat från ostrukturerade data, baserat på semantisk likhet. - Retrieval augmented generation (RAG)
Utöka resonemangsmöjligheterna hos LLM:er med flöden av din egen realtidsdata, för att skapa ”GenAI-appar” vilka blir unikt skräddarsydda för ditt företags krav och behov.
Med MongoDB Atlas Vector Search låser du upp den fulla potentialen ur din data, oavsett om den är strukturerad eller ostrukturerad. Dessutom kan du smidigt dra nytta av användningen av AI och LLM för att lösa kritiska affärsutmaningar. Detta är möjligt tack vare att Vector Search är en del av MongoDB Atlas utvecklardataplattform, som använder en flexibel dokumentdatamodell och enhetliga API:er som ger en konsekvent upplevelse. För att säkerställa att du drar full nytta av kraften i Atlas Vector Search har MongoDB tagit fram ett robust ekosystem av AI-integrationer. Det gör det möjligt för utvecklare att använda och bygga med sina, sedan tidigare, favorit-LLM:er eller -ramverk.
Fler fördelar med MongoDB Atlas Vector Search
MongoDB Atlas Vector Search drar även nytta av den nya dedikerade MongoDB Atlas Search Nodes-arkitekturen. Den möjliggör bättre optimering för rätt nivå av resurser för specifika behov av arbetsbelastningar. Söknoder tillhandahåller dedikerad infrastruktur för MongoDB Atlas Search- och Vector Search-arbetsbelastningar, vilket gör att utvecklare kan optimera beräkningsresurser och sätta upp fullskaliga sökkriterier oberoende av databasen.
MongoDB Atlas Söknoder ger även bättre prestanda i stor skala, levererar arbetsbelastningsisolering, högre tillgänglighet och möjligheten att bättre optimera resursanvändningen. I optimala fall kan frågetiden kortas med 60 procent för vissa arbetsbelastningar.
Som tillägg till beräkningskapabla söknoder – som funnits tillgängliga redan i den offentliga förhandsversionen, – har den publika versionen även utrustats med ett minnesoptimerat alternativ med lägre processorkrav, vilket är optimalt för vektorsökning i produktion. Detta gör att problem som varit kopplade mot resursbrist orsakad av att databas och sökning tidigare delade samma infrastruktur i dessa miljöer nu är helt borta.
Det finns ett stort antal fördelar med att använda MongoDB Atlas Vector Search. Här är de mest påtagliga, för alla typer av scenarion och användare.
- Semantisk förståelse
I stället för att söka efter exakta matchningar, möjliggör vektorsökning semantisk sökning av olika typer av data, inklusive text, men även ostrukturerad data som ljud och bilder. Detta innebär att även om frågeorden inte finns i indexet, men meningarna av fraserna är liknande, kommer de fortfarande att betraktas som en matchning vilket ger en högre flexibilitet. - Effektivitet
Genom att lagra vektorerna tillsammans med originaldata undviks behovet av att synkronisera data mellan applikationsdatabas och vektorlager vid både fråge- och skrivtid. - Konsekvent
Lagring av vektorerna tillsammans med data säkerställer att de alltid associeras med rätt data. Detta kan vara viktigt i situationer där vektorgenereringsprocessen kan förändras över tid. Genom att lagra vektorerna kan vi vara säkra på att alltid har rätt vektor för en given databit. - Enkelhet
Att lagra vektorer tillsammans med data förenklar den övergripande arkitekturen för applikationerna. Då vi inte behöver underhålla en separat tjänst eller databas för vektorerna, minskas både komplexiteten och potentiella felpunkter i systemet. - Skalbarhet
Tack vare kraften i MongoDB Atlas, skalas vektorsökning på MongoDB horisontellt och vertikalt, vilket gör det möjligt att driva de mest krävande arbetsbelastningarna, oavsett mängden data.
För att lära dig mer om MongoDB Atlas Vector Search kan du se en kort introduktionsvideo här, eller så kan du besöka denna sida för en guidad genomgång hur du kommer i gång.
MongoDB Atlas Stream Processing
Nästa tjänst, som i skrivande stund är i en enskild förhandsvisning, är MongoDB Atlas Stream Processing. Denna tjänst skapar förutsättningar att skapa ”eventdrivna” applikationer genom att kontinuerligt inta, transformera och bearbeta realtids-dataströmmar från en händelsemeddelandeplattform (som Apache Kafka) för att utföra olika funktioner. Detta innebär att utvecklare kan skapa enkla filter för att ta bort onödiga data, utföra aggregering för att räkna eller summera data efter behov, skapa så kallade stateful windows och mer.
Tack vare tjänsten kan utvecklare även, för första gången, använda en unifierad plattform – över API, frågespråk (query language) och datamodeller – för att kontinuerligt bearbeta strömmande data tillsammans med de kritiska applikationsdata som lagras i deras databas. Det enar data i rörelse med data i vila på ett effektivt och flexibelt sätt och underlättar när utvecklare bygger applikationer som kräver bearbetning av komplexa händelsedata i större skala.
MongoDB Atlas Stream Processing gör det även möjligt för utvecklare att bygga aggregeringspipelines för att kontinuerligt söka efter, analysera och reagera på strömmande data i mer eller mindre alla format, utan de fördröjningar som normalt är förknippade med batch-bearbetning av data.
Jämförelsevis fungerar inte batch-bearbetning på kontinuerligt producerade data, utan baseras på data som samlats in under en viss tidsperiod, och som sedan bearbetas mer statiska data efter behov vilket gör att vi tappar tid.
Med MongoDB Atlas Stream Processing är det lika enkelt att söka efter data från Apache Kafka som MongoDB. Allt som behövs är att du definiera en källa, önskade aggregeringssteg och en uppsamlingsplats för att snabbt bearbeta dina Apache Kafka-dataströmmar.
Dessutom utförs kontinuerlig schemavalidering för att kontrollera att händelser är korrekt utformade före bearbetning, för att upptäcka eventuell meddelandekorruption samt för att i tid upptäcka sent inkommande data som har missat sitt fönster för bearbetning.
MongoDB Atlas Stream Processing låter dig även analysera och bearbeta specifika datafönster med fast storlek i en kontinuerlig dataström, vilket gör det enkelt att upptäcka mönster och trender.
Till detta materialiseras kontinuerligt vyer i Atlas databassamlingar eller streamingsystem som Apache Kafka, för att upprätthålla nya analytiska vyer av data vilka i nästa led kan användas som grund för beslutsfattande och vidare handling, och på detta sätt underlätta och avlasta för systemansvariga.
För att läsa mer om MongoDB Atlas Stream Processing kan du besöka den här sidan.
Artificiell intelligens – en naturlig del i allas framtid
Trots att MongoDB:s tjänster och lösningar är applicerbara och passar in i de flesta miljöer – från Edge Computing, IOT, mobila tjänster och betallösningar till alla typer av finansiella tjänster, hälsosektorn, den publika sektorn, tillverkning och detaljhandeln med många flera – så är det ett (1) område som i allt större utsträckning omfattar samtliga av dessa, samtidigt som det står på egna ben. Det gäller AI rent generellt och generativ AI mer specifikt. Vi avslutar därför denna artikel med att lyfta MongoDB:s styrkor inom AI-området där vi övergripande kan säga att MongoDB Atlas förenar operativa, analytiska och generativa AI-datatjänster för att effektivisera byggandet av AI-berikade applikationer.
För att vinna i den digitala ekonomin, en ekonomi som förespås omsätta 400 miljarder dollar år 2027, måste företag göra sina applikationer smartare. Smartare appar använder data, AI och analys för att engagera användare med naturligt språk, generera insikter och självständigt vidta åtgärder.
För att bygga den nya generationens appar måste vi göra saker annorlunda. Vi kan inte längre lita på att bara kopiera vår data från operativa system till centraliserade analyssystem. Istället måste vi använda en ny klass av AI och analysbehandling direkt till datakällan – till själva applikationerna. Detta är en lösning som kallas för applikationsdriven intelligens.
De flesta moderna applikationer utnyttjar olika former av dataanalyser för att skapa mer meningsfulla och reaktiva kundupplevelser. Genom att använda maskininlärningsmodeller automatiserar AI komplexa beslut för personifiering, bedrägeriförebyggande, förutsägande underhåll med mycket mera.
Den trend vi kunna följa under senare tid, som även accelererar för varje år, är de generativa AI-förstärkta applikationerna som tar den prediktiva analysen till nästa nivå när det kommer till att skapa helt nya upplevelser för användaren. Vi hittar här lösningar som sträcker sig från olika typer av från ”chatbottar” – som erbjuder personlig support inom exempelvis vården eller detaljhandeln – till allt mer avancerade AI-genererade bilder, kod, ljud och video, vilka samtliga kommer från naturliga språkinmatningar och från data i realtid
När vi tittar till stommen för dagens och morgondagens butiker och system skiljer vi lite grovt på två typer av så kallade functional stores, eller system, som används för att lagra och betjäna attribut som används i maskininlärningsmodeller. Vi har offlinebaserade functional stores vilka prioriterar hög genomströmning och primärt används för modellträning. Sedan har vi slutledningsbutiker, eller onlinefunktionsbutiker, vilka prioriterar låg latens för analys och slutledning i realtid och för liveapplikationer. Tack vare att MongoDB och MongoDB Atlas täcker både moln- och on-prem-baserade system, skapas även optimala förutsättningar för att tillgodose båda dessa aspekter av AI-inlärning och utnyttjande.

MongoDB Atlas – den naturliga kärnplattformen för artificiell intelligens
För att skapa bästa tänkbara plattform för AI-drivna appar krävs ett flertal komponenter i själva kärnan av de system som används. MongoDB Atlas erbjuder både en bred grund och en ständigt växande skara av tjänster som underlättar denna process, men vi har valt att lyfta fram ett par av de primära som gör det möjligt för utvecklare att på enklast möjliga vis bygga nya eller anpassa befintliga appar för framtidens krav och behov.
- Enhetlig hantering av olika datatjänster
MongoDB Atlas förenklar AI-livscykeln genom operativa, analytiska och AI-datatjänster som utnyttjar en enda datamodell och en enda fråge-API ovanpå en flexibel, skalbar och säker multimolnplattform. - Flexibel dokumentmodell
En plattform som gör det möjligt att förnya och experimentera med nya parametrar och data av alla slag genom att landa, lagra och indexera data utan långvarig schemadesign eller fortlöpande modifieringar. - Optimerad lagring och nivåindelning
Med MongoDB Atlas kan vi uppnå hög genomströmning och låg latens för slutledningslagring genom att kombinera datanivåer och sammanslagna data med rad- och kolumnindexering i en horisontellt skalbar operativ databas. - Uttrycksfullt, välbekant API
Förbättra produktiviteten för utvecklare och ML/AI team (maskininlärning/artificiell intelligens) med ett enda uttrycksfullt fråge-API som förenklar allt från databeredning och modellträning till slutledning och kunskapsinhämtning. - Integrerade vektorfunktioner
Utöka och förbättra applikationer med generativ AI genom, en i plattformen, integrerad vektorfunktion samt dokumentlager utan behov av extra infrastruktur att tillhandahålla, säkerställa och hantera. - Omfattande integration
Bygg AI-förstärkta applikationer med den ledande utvecklarplattformen för multi-cloud-strukturer samt ett mycket gediget AI-partnerskap, vilket även omfattar MLOps-plattformar (Machine Learning Operations) samt öppen källkodbaserade LLM:er.
Intressanta länkar
- För att läsa mer om MongoDB och applikationsdriven intelligens klicka här.
- För att ansöka om att medverka i MongoDB AI Innovators Program klicka här.
- För att lära dig mer om MongoDB Atlas och LLM:s klicka här.
- För att få tillgång till MongoDB:s övriga resurser gällande AI-driva appar klicka här.